Demystifying Large Language Models (LLMs)
An In-Depth Guide to Architecture, Training, Applications, and Future Trends

Introduction: The Rise of Language Intelligence
Language has always been central to how humans think, feel, and innovate. Yet for decades, making machines understand human language seemed like an unsolvable puzzle.
That changed with the rise of deep learning, leading to the development of Large Language Models (LLMs) — a revolution that brought computers a step closer to natural human interaction.
Today, LLMs are not just generating text but assisting in coding, powering search engines, aiding scientific research, and reshaping industries.
But what exactly are they, and why have they become so transformative? Let’s dive deep.
What Are Large Language Models?
Large Language Models (LLMs) are powerful deep neural networks trained on enormous amounts of text to understand, generate, and manipulate human language with remarkable fluency.
Built using self-supervised learning techniques, these models are designed to predict the next word or fill missing words in a sentence, enabling them to internalize the patterns, grammar, style, and factual knowledge embedded in the data.
The ultimate goal is to make machine communication as natural, flexible, and informative as human conversation.
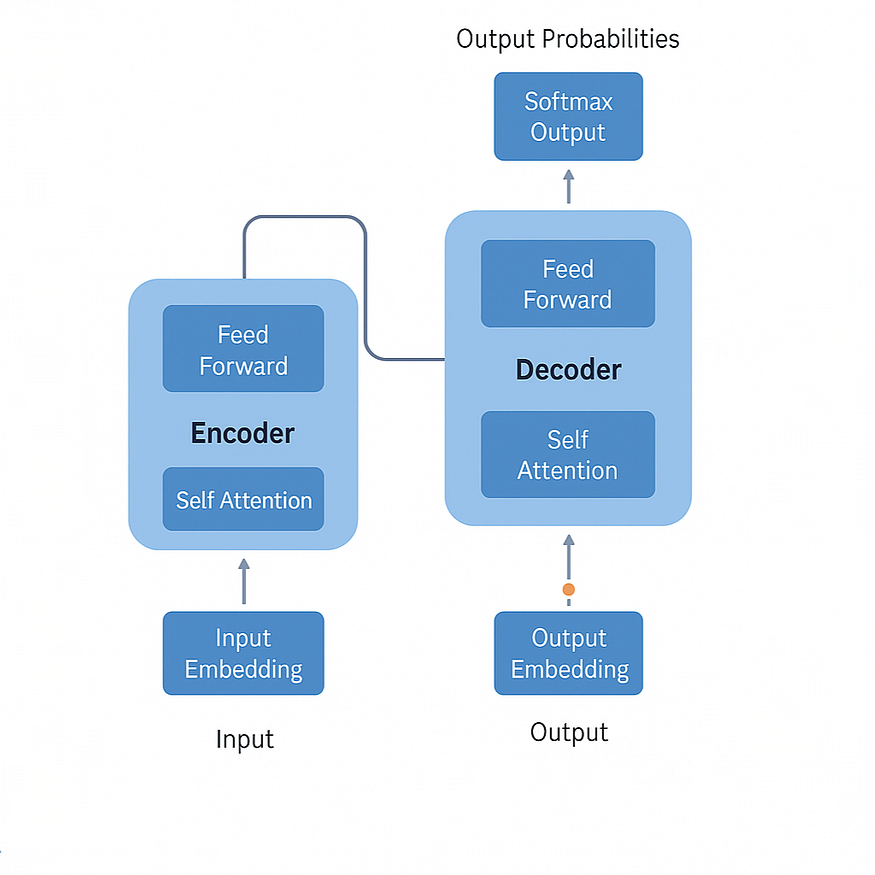
Architecture: The Transformer — The Engine Behind LLMs
At the core of almost every modern LLM lies a breakthrough architecture called the Transformer, introduced in 2017 by Google in a Paper published named Attention Is All You Need.
Main Components of a Transformer:
Input Embedding
Positional Encoding
Self-Attention Mechanism
Feedforward Networks
Residual Connections and Layer Normalization
Output Layer
Input Embedding
Before the model can understand words, it needs to represent them numerically. Input embeddings convert words or tokens into high-dimensional vectors, where words with similar meanings lie closer together.
This mathematical representation enables the model to capture subtle semantic relationships and contextual clues.
Positional Encoding
While embeddings capture what words mean, Transformers also need to know where words appear in a sequence because, unlike humans, models don’t inherently sense order.
Positional encodings inject information about the position of each word, helping the model grasp syntax and meaning derived from word order — distinguishing, for example, between “dog bites man” and “man bites dog.”
Self-Attention Mechanism
The self-attention mechanism allows every word to consider other words in the input when forming its own meaning. For instance, the word “bank” in “river bank” should focus on “river” to disambiguate itself from a “financial bank.”
By dynamically weighting the relevance of surrounding words, self-attention enables the model to interpret language contextually, making responses more coherent and intelligent.
Feedforward Networks
After self-attention enriches word representations with context, feedforward networks — standard layers of neural computation — further transform and refine these representations, enhancing the model’s capacity to capture complex relationships.
Residual Connections and Layer Normalization
To ensure information flows smoothly through deep networks without degrading, Transformers employ residual connections and normalization techniques. These mechanisms stabilize learning and speed up training, allowing the construction of very deep — and therefore very powerful — models.
Output Layer
Finally, the model generates probabilities for the next word or output token, culminating in fluent and context-aware text generation.
(Imagine it as a reader who constantly reviews and weighs every word before deciding how to continue writing.)
How Are LLMs Trained?
Training a Large Language Model is an enormous task involving several stages:
1. Data Collection
Training begins by amassing vast and diverse corpora: books, websites, research papers, code repositories, and more.
This wide-ranging data ensures the model captures a rich blend of human knowledge, culture, and language variations, equipping it to handle a multitude of topics and communication styles.
2. Training Objective
Most LLMs are trained using objectives like:
Next Word Prediction: Guessing the next word in a sentence.
Masked Word Prediction (for models like BERT): Predicting missing or hidden words within a sentence.
These objectives push models to learn grammatical structures, logical reasoning, factual knowledge, and creativity, all by attempting to minimize prediction errors.
3. Infrastructure
Given the scale of LLMs, training them demands massive computational infrastructure — often spanning hundreds or thousands of GPUs or TPUs distributed across specialized server farms.
Without such computational might, processing and learning from trillions of tokens would be practically impossible.
Capabilities of LLMs: What They Can Do
When properly trained, LLMs unlock an astonishing range of capabilities:
Text Generation: Writing essays, stories, news articles, and marketing content.
Summarization: Condensing books, research papers, or reports into concise summaries.
Question Answering: Providing quick, precise answers across domains.
Code Generation: Writing, debugging, and even explaining programming code.
Language Translation: Seamlessly converting text between different languages.
Reasoning and Problem-Solving: Tackling logic puzzles, math problems, and strategic games.
These abilities stem from the model’s deep internalization of language patterns, relationships, and factual knowledge accumulated during training.
Real-World Examples: Leading LLMs
OpenAI’s GPT Family
The GPT series exemplifies the concept of versatile, general-purpose LLMs that can handle diverse tasks without explicit retraining. Their strength lies in their adaptability — writing poetry one moment and answering technical questions the next.
Meta’s LLaMA Models
LLaMA models are designed with researchers in mind, offering high-quality performance in a more accessible, open-weight format. They aim to democratize cutting-edge AI research by allowing broader experimentation.
Anthropic’s Claude
Claude models are built with an emphasis on safety, reliability, and ethical interactions, reflecting growing concerns about the societal impact of AI systems.
Google’s Gemini
Gemini represents a shift toward multimodal capabilities — handling not just text but images, videos, and other media — signaling a future where AI systems understand the world more like humans do.
Challenges and Limitations
Even the most advanced LLMs are not without weaknesses:
Hallucinations: Sometimes, models fabricate facts, demonstrating confident but false outputs — a critical concern for applications in fields like healthcare or law.
Bias and Fairness: Since models learn from real-world data, they inevitably inherit societal biases. Responsible model design requires identifying and mitigating these biases.
Interpretability: Understanding why a model made a particular decision remains difficult, creating challenges in debugging and building trust.
Environmental Impact: The energy demands of training and running LLMs raise environmental sustainability concerns that researchers are actively working to address.
Emerging Trends: What’s Next for LLMs?
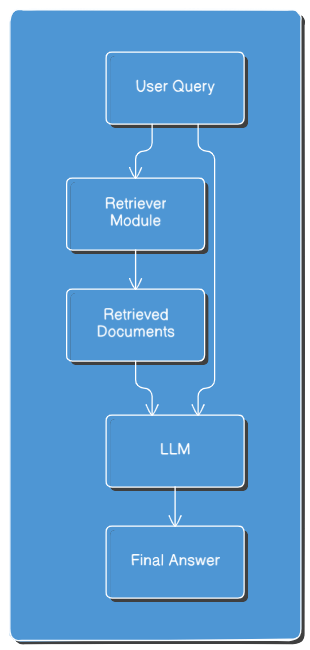
Retrieval-Augmented Generation (RAG)
Rather than relying solely on internalized knowledge, RAG systems retrieve relevant documents during inference and use them to generate more accurate, up-to-date responses.
This technique expands an LLM’s effective memory, enabling more reliable and factual interactions.
Fine-Tuning and LoRA/QLoRA
Instead of retraining an entire large model for every task, fine-tuning adapts a pre-trained model to specialized domains like medicine, finance, or legal writing, with smaller, task-specific datasets.
Techniques like LoRA (Low-Rank Adaptation) and QLoRA (Quantized LoRA) make this process even more efficient by updating only certain parts of the model, dramatically reducing memory requirements and computational costs.
This efficiency allows smaller organizations and even individuals to create highly specialized models without needing a supercomputer.
Mixture of Experts (MoE)
MoE models activate only relevant parts of the network based on the task at hand. Instead of using the entire model for every query, they selectively route inputs through smaller expert networks, improving efficiency while maintaining high performance.
Multimodal Intelligence
The next frontier is multimodal models that can understand and generate not just text, but also images, audio, and video, enabling AI systems to perceive and interact with the world in a more holistic, human-like way.
Conclusion: Shaping the Future of Intelligence
Large Language Models have evolved from niche research experiments into transformative technologies reshaping industries, education, communication, and creativity.
As we push forward, combining breakthroughs like retrieval augmentation, fine-tuning, efficiency optimizations, and multimodal learning, we are steadily building AIs that are not only more powerful but also more grounded, trustworthy, and accessible.
The promise of LLMs is enormous, but realizing it fully will require a thoughtful balance between innovation and responsibility.
The future is not just about smarter machines; It’s about building machines that make humanity smarter.

